What is Information Leakage, and how do you prevent it?
One of the most commonly found flaws in web applications and mobile applications is information leakage. But what is information leakage, why is it a problem, and how do we prevent it from happening with our own applications?
Information leakage is a common problem
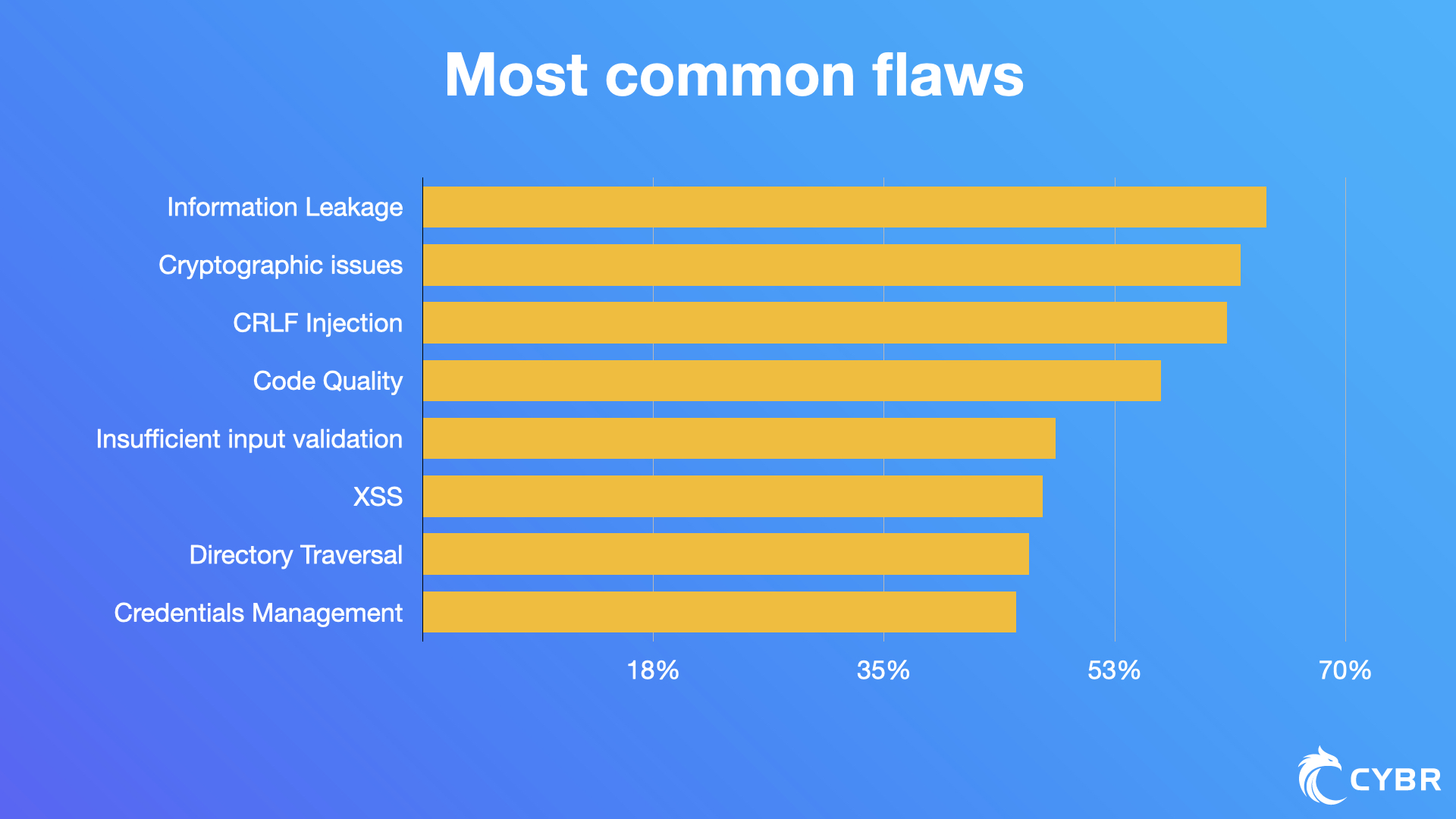
A Veracode State of Software Security report shows that 83% of the 85,000 applications they tested had at least one security flaw, and 20% of all apps had at least one high severity flaw.
The most common types of flaws in the report are:
- Information leakage (64%)
- Cryptographic issues (62%)
- CRLF injection (61%)
- Code quality (56%)
- Insufficient input validation (48%)
- Cross-site scripting (47%)
- Directory traversal (46%)
- Credentials management (45%)
While we cover all 8 flaws in this blog post, including information leakage, this post will go into further details to provide a broader understanding of what information leakage is, why it can turn into a security problem, and how to prevent it with our applications.
What is information leakage?
When information leakage is detected in an application — regardless of whether it is a web or mobile app — it means that the application revealed sensitive information that it shouldn’t have.
That sensitive information can be anything from a simple developer comment, all the way to a username/password visible in plain text.
So not all information leakage is catastrophic. In fact, it’s usually not a major issue. But, when left unchecked, or when discovered by a skilled threat agent, it can lead to more complex attacks that could end up seriously compromising your application and/or your organization.
Example #1 – Comments left unchecked
Let’s take a look at one of the most basic examples: information leakage caused by a developer comment that was deployed to production.
Not all comments in production are bad. Most of the time, they can be completely harmless. The issue comes into play when comments can leave clues to an attacker as to how:
- The backend system works
- The networks powering this application are configured
- How security controls are implemented (or the lack of their implementations)
- Whether you are running outdated and vulnerable software
- and more
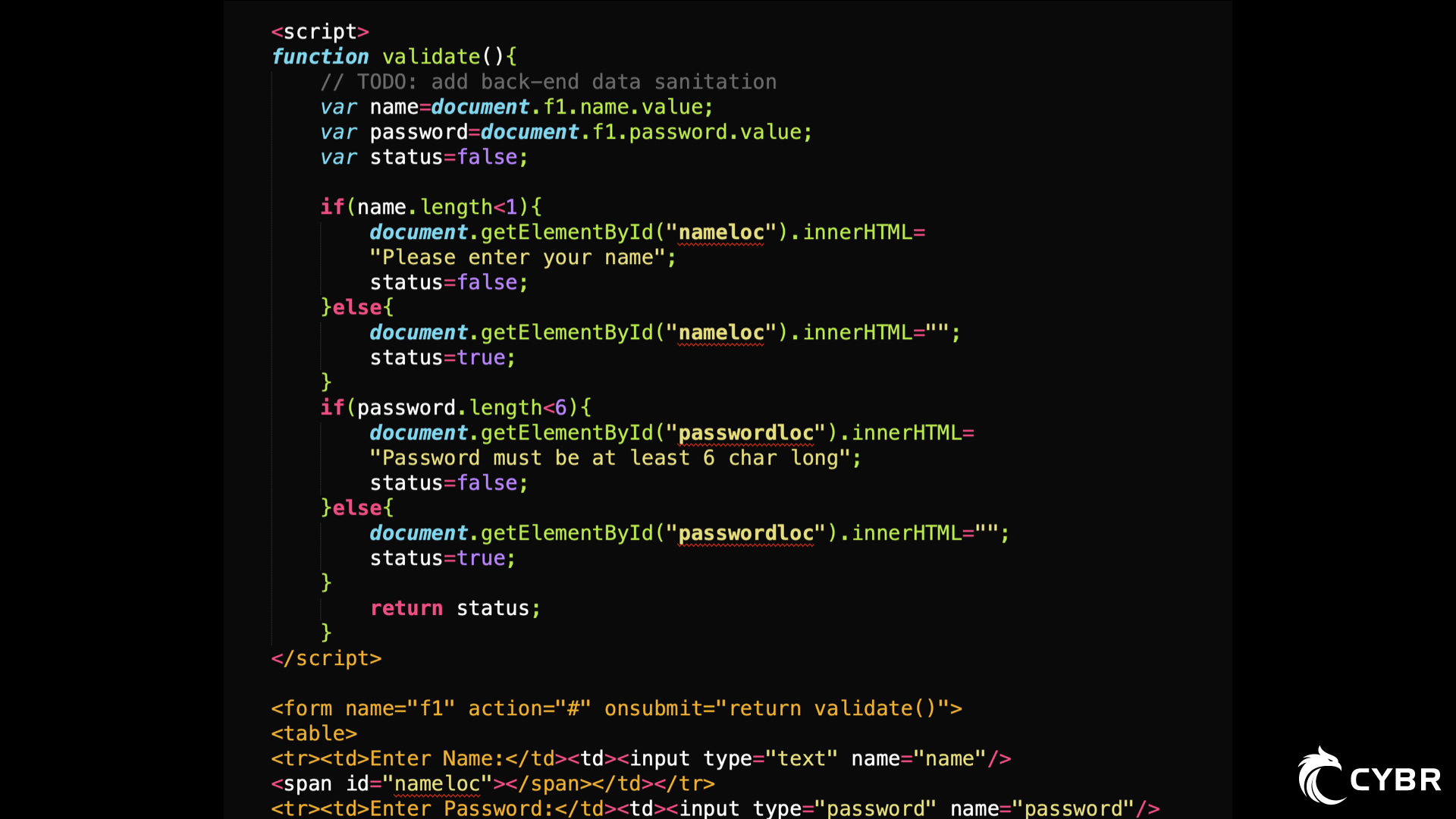
In this screenshot, a developer working on this project left a comment stating that:
//TODO: add back-end data sanitation
If I’m a threat agent who wants to attack your application, and I see this comment, I now have an indication that there may not be any backend data sanitation implemented. So, even if the frontend employs data sanitation, I can attempt to bypass the frontend entirely and send my payload directly to the backend, and if there really is a lack of backend data sanitation, it’s very likely that I can slip something through that could do some damage.
The reason that this is possible is because frontend sanitation only checks data as it is being entered, or once it’s submitted, through the browser.
Then, that data gets sent to the backend code, at which point it should be checked again. If I know where the form is POSTing data to (which is easy to find out), and what data it is sending (also easy to find out), then I could construct my own request to the backend with my payload, and completely bypass the frontend restrictions.
If there is no sanitation happening there, it’s also very likely that is missing other security controls. Maybe that means I can execute SQL injections, XSS attacks, or other types of attacks.
Whatever the case may be, the simple comment that is only a few words long has led me down a probable path of attack.
Is that attack vector not still there regardless of whether the comment was removed? Yes, of course. But the simple fact that the comment was discovered could literally remove weeks of effort. Before finding it, the attacker might have given up or simply overlooked this vulnerability. Now, instead, it’s like giving them the keys to our home on a silver platter.
Example #2 – Bad error handling
Have you ever navigated to a website, clicked around, and then received an error message that looked something like this?
Error executing SQL query: SELECT Currency_Id, name, currentPrice, pastPrice FROM Currencies WHERE name LIKE '' or '1'='1';';Code language: JavaScript (javascript)Not exactly that, of course, but something that mentioned ‘Error executing SQL query.’
Chances are that you have, even if not recently (hopefully not recently).
This type of information leakage can be a lot more severe than the one we explored previously, because it provides far too much information in regards to how the application is processing:
- User inputs
- SQL queries
- Exceptions
As an attacker, seeing this pop up gives me a massive advantage, because I can now explore reactions to my inputs.
First of all, I now know that my inputs are not being escaped, validated, or sanitized at all. That opens the application up to serious risk.
Second, I now know that there is a Currencies table, as well as Currency_Id, name, currentPrice, and pastPrice columns in that table.
Third, I know that this specific query will let me manipulate anything after WHERE name LIKE '. So at a minimum, I can get all of the currency information from the table, even if my privileges aren’t supposed to be high enough for me to have access to that information.
Fourth, I now know that this input/form, application, and database are missing important security controls. Chances are that other forms in the application may be vulnerable…including the users table, or anything else of potentially high value.
At this point, I can perform information gathering using manual techniques as well as automated tools to then exploit this database table, and potentially others as well.
Again, its important to re-iterate that even if we, as the developers of this application, had hidden this error message, it does not mean that our database is now all of a sudden safer. The SQL injection vulnerabilities would still be there, however, it makes the attacker’s job much more difficult, especially if they are not highly skilled.
Example #3 – Mobile information leakage
Mobile applications are notoriously bad about leaking information.
As we covered in this blog post on the 3 most common mobile application security risks, research by NowSecure from 2018 tested apps in the App store and Google Play store to determine how many of the published apps violated OWASP’s top 10 mobile application security risks.
They then compiled the number of apps that their tests found to be violating at least 1 of the OWASP top 10 risks, and finally broke them down by which of the risks were most often violated.
Not only did they find that 85% of apps violated at least one of the top 10 risks, but the top 3 risks have to do with leaking data:
- Insecure Data Storage
- Insecure Communication
- Extraneous Functionality
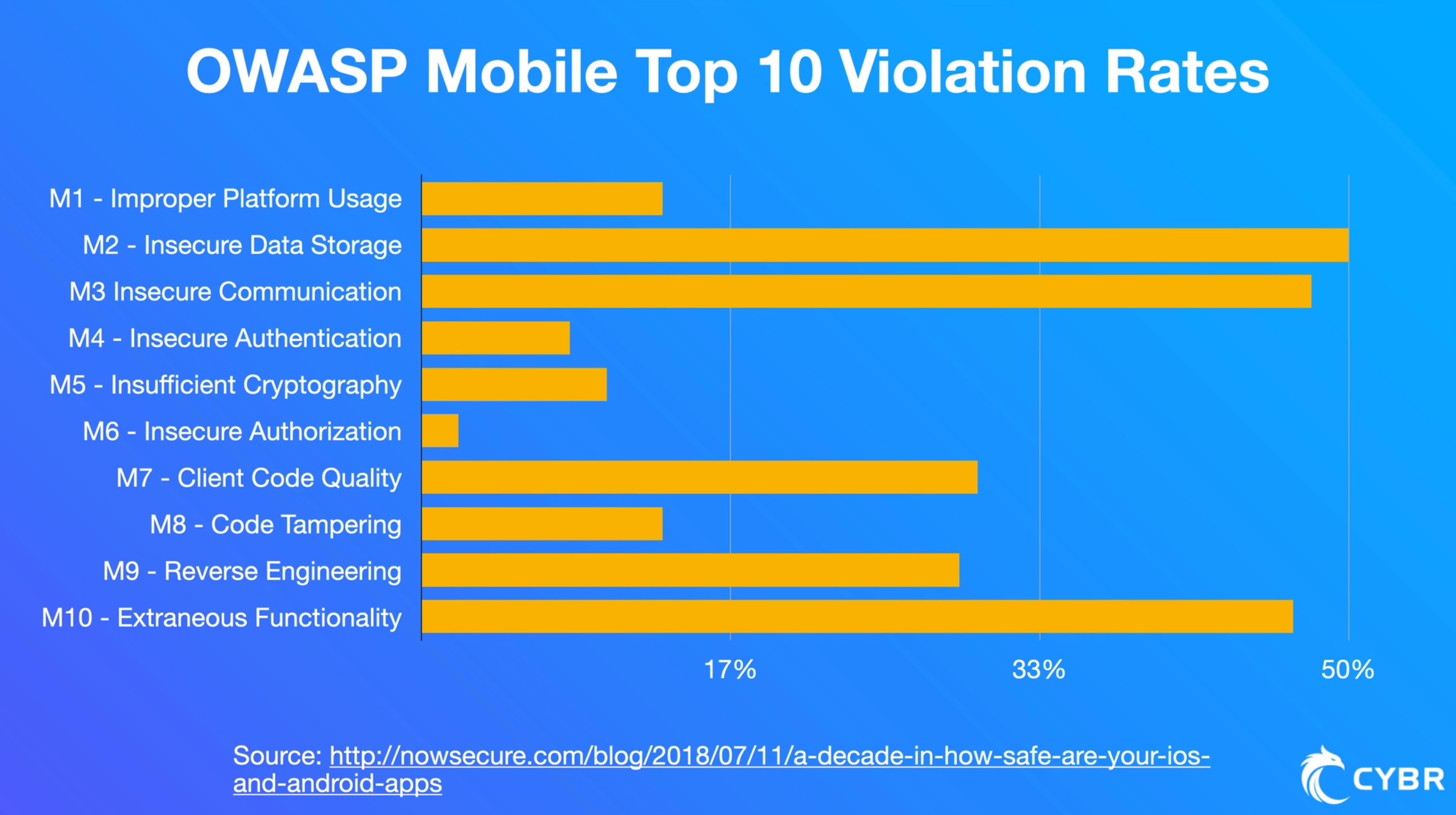
Since we covered these three top risks in more depth in this article, we won’t do that again here. What we will do, however, is provide an illustration of why these 3 risks can lead to information leakage.
Insecure Data Storage
If your application’s or user’s data is not properly secured when stored on devices (or even in the cloud), then it can be fairly easy for an attacker to gain access to that information, without necessarily having access to the victim’s mobile phone. All it could take is malware downloaded by accident, and that malware could access the device’s storage.
Insecure Communication
On the other hand, if your application’s data storage is locked down and secure, but communication isn’t properly secured, we still have a problem. Communication can mean anything from data being transferred to – and from – your mobile app to your backend servers, via Bluetooth to another device, via NFC tags, and the list goes on.
All it takes is one piece of information being communicated without proper encryption, such as user session and authentication information, for an account to be compromised.
Extraneous Functionality
Again, even if we have very secure data storage and encrypted communication, but we’ve released extraneous functionality that leaks information to a threat agent that then provides the attacker with elevated privileges, we could now have an even worse situation on our hands that goes beyond privacy violation or identity theft.
How to prevent information leakage in your applications
Information leakage is quite broad when it comes to labeling the impact that it can have on our applications, its users, and our organization.
The reason for this is because it can be anything from a trivial release of information that won’t lead to anything serious all, to providing an attacker with just the right information for them to completely infiltrate our systems or extract critical data.
This is part of what makes it difficult to prevent information leakage. We can’t just look in a few places because the scope is far too wide. But — especially as our application grows in size and complexity — we also can’t inspect every inch in great detail.
Heck, even if we spend time inspecting everything in development and staging, we still have to make sure nothing slipped into production!
With that said, there are a number of steps we can, and should, take to diminish the odds of our applications making it on next year’s list of vulnerable apps. Let’s take a look.
Prioritizing
When something becomes too broad, too complex, and too time-consuming, we inevitably have to prioritize. Since there are too many factors to take into account, and too many potential risks or attacks, we have to narrow it down.
One great way to narrow things down is by leveraging existing frameworks, tools, and processes such as Threat Modeling. We cover this in our How to get started with Application Security post.
Manual reviews
This is probably the last answer you wanted to see, but it needs to be mentioned. There is no silver bullet when it comes to most things in cybersecurity, and finding code or systems that leak information is no exception.
In the first example we looked at, a human being could look at that code being checked into our repository for review and see it within minutes of glossing over, where automated tools may not pick it up as an issue.
Automated scans
With that said, there are automated tools out there at our disposal, so why not use them? Even if they can’t catch everything, they definitely can catch the low-hanging fruit and save time.

By implementing automated scans, we can detect code, comments, configurations, etc…that could lead to information leakage, before it even makes it to a human being for review, and definitely before it makes it out to our production environments.
For example, if we have a configuration flag being used in development and staging in order to enable debugging for our development teams to troubleshoot, but we’re supposed to swap out that flag to disable debugging in production, we can make sure that our automated tools check for that flag to be disabled. If it’s not, it completely blocks that code from making it to the next steps in your DevOps pipeline and notifies you of the issue.
Pentesting
While not the number one option for reasons listed in this lesson of our free course on Introduction to Application Security, pentesting can also help find information leakage since we’re taking the approach that an attacker would.
So, if our manual and automated tests failed to find all areas where our application is leaking information, hopefully our pentesting efforts can find and help fix the issue before someone else finds it and exploits it.
Get rid of information leakage and defend your apps against other risks
As you venture on your journey to rid your application of information leakage, don’t stop there! Learn to understand, recognize, and defend against OWASP’s top 10 web or mobile application security risks by taking our free Introduction to Application Security(AppSec) course. If you prefer reading over watching videos, we also have a free ebook version!






Responses